SQL-Tutorial - Erste Schritte mit SQL
Dies SQL Tutorial für Einsteiger erläutert die wichtigsten SQL-Befehle, einschließlich grundlegender Datenbankenkonzepte, anhand von Beispielen. Die Beispiele beziehen sich auf eine University-Datenbank, die Daten über Studiengänge, Module, Studenten und Prüfungen verwaltet, und als Datenhaltungsschicht für eine Webanwendung verwendet werden soll. Als Datenbankmanagementsysteme verwenden wir einerseits MariaDB / MySQL als Teil des XAMPP-Pakets und andererseits SQL Server. Zum schnellen Nachschlagen der am häufigsten genutzten SQL-Befehle kann direkt die SQL-Kurzreferenz verwendet werden, diese bietet eine tabellarische Übersicht mit Filter und Suche. In Teil 2 "JDBC-Tutorial" wird die Verwendung der Java Database Connectivity-API zum Erstellen eines Java-Clients für eine MySQL-Datenbank beschrieben.
Motivation
SQL ist die meistgenutzte Datenbanksprache, und dies seit 1970, als SQL noch SEQUEL hieß
und E.F. Codd in seinem bahnbrechenden Artikel "A Relational Model of Data for Large Shared Data Banks"
die Grundlagen relationaler Datenbanken legte.
Heute gehört SQL zum Werkzeugkasten von Informatikern und Ingenieuren, ungeachtet dessen, ob Datenbanksysteme
systematisch gelernt wurden, oder ob man sich die Sprache on-the-job selbstständig beigebracht hat.
Das Erlernen von SQL wird dadurch erleichtert, dass viele
Datenbankmanagementsysteme (DBMS) über grafische Benutzeroberflächen verfügen, die
die Generierung von SQL-Skripten unterstützen und die dabei generierten SQL-Befehle
optional auch anzeigen.
SQL ist standardisiert, d.h. wer die SQL-Syntax beherrscht, kann Datenbanken für verschiedene
DBMS entwickeln: Microsoft SQL Server, MySQL /MariaDB, Oracle, PostgreSQL etc.
MariaDB und MySQL sind verwandte quelloffene DBMS, die in vielen Webanwendungen als Backend eingesetzt werden. Für das Datenbankmanagement stehen stehen gleich zwei Tools zur Verfügung: phpMyAdmin als webbasierte Benutzeroberfläche und MySQL Workbench als Desktopanwendung. MariaDB / MySQL ist bei Einsteigern aus mehreren Gründen sehr beliebt:
- (1) wegen der benutzerfreundlichen Datenbankverwaltung per phpMyAdmin
- (2) wegen der einfachen Installation, z.B. als Teil des Programmpakets XAMPP
- (3) wegen der Verfügbarkeit unter verschiedenen Betriebssystemen: Windows, Linux und Mac OS.
Microsoft SQLServer ist ein kommerzielles DBMS, das in der Developer oder Express-Version für Lehre und privaten Gebrauch kostenlos verwendet werden kann. Während der Einsatz von SQL Server lange Zeit auf das Windows-Betriebssystem eingeschränkt war, kann das DBMS seit 2017 auch unter Linux eingesetzt werden. SQL Server wird in vielen Unternehmen eingesetzt und die Verwendung der kostenlosen Versionen ist ein guter Weg, um die Komplexität eines kommerziellen DBMS kennenzulernen.
Übersicht
Das Tutorial ist in sieben Abschnitte gegliedert, die die SQL-Syntax
an einfachen Beispielen erklären und aufeinander aufbauen.
Als Vorbereitung: MySQL via XAMPP oder SQL Server installieren und die jeweils passende
Beispiel-Datenbank "University" per hier verlinktem Skript erstellen.
CreateDatabaseUniversity(MySQL).sql
CreateDatabaseUniversity(SQLServer).sql
- 1 Grundlegende Konzepte
1-1 Was ist eine relationale Datenbank?
Tabelle Beziehung View Constraint Primärschlüssel Fremdschlüssel Lebenszyklus einer Datenbank
1-2 Kategorien von SQL-Befehlen: DML, DDL, DCL
1-3 Aufbau eines SQL-Befehls
Qualifizierte Namen Kommentare SQL-Funktionen - 2 Vorbereitung: DBMS installieren
DBMS MySQL XAMPP SQL Server - 3 Beispiel-Datenbank University
Anforderungen ER-Diagramm - 4 DML-Befehle: Datenabfrage und -Manipulation
4-1 SELECT: Daten abfragen
AS ORDER BY DISTINCT JOIN Unterabfrage GROUP BY
4-2 INSERT: Daten einfügen
4-3 UPDATE: Daten ändern
4-4 DELETE: Daten löschen - 5 DDL-Befehle: Datenbankstruktur erstellen und ändern
5-1 CREATE: Strukturen anlegen
Groß- und Kleinschreibung CREATE DATABASE USE CREATE TABLE CREATE VIEW
5-2 ALTER: Strukturen ändern
ALTER TABLE Spalten hinzufügen Fremdschlüssel hinzufügen
5-3 DROP: Strukturen löschen
5-4 TRUNCATE: Inhalte endgültig löschen - 6 Benutzer- und Rechteverwaltung
Mehrbenutzerbetrieb Rollen
6-1 CREATE USER: Benutzer anlegen
6-2 GRANT: Rechte vergeben
6-3 REVOKE: Rechte entziehen - 7 Transaktionen
COMMIT ROLLBACK
1 Grundlegende Konzepte
| Top |
SQL ist eine deklarative Datenbanksprache, die den kompletten Lebenszyklus einer relationalen Datenbank unterstützt: Datendefinition (data definition), d.h. das Erstellen von Datenbanken und deren Strukturen, Datenmanipulation (data manipulation), d.h. das Einfügen, Ändern, Löschen und Abfragen von Daten, und Datenkontrolle (data control), d.h. die Vergabe von Rechten an der Verwendung der Daten.
1-1 Was ist eine relationale Datenbank?
Eine Datenbank ist im allgemeinsten Sinn eine logisch zusammenhängende Datenstruktur, die für einen bestimmten Zweck entworfen, mit Daten gefüllt und als Datenquelle in Anwendungen verwendet wird. Eine relationale Datenbank besteht aus einer Menge Tabellen mit Beziehungen zueinander, deren Zustand stets konsistent sein muss, dies wird durch Constraints / Integritätseinschränkungen sichergestellt. Im Unterschied dazu werden in nicht-relationalen bzw. NoSQL-Datenbanken die Daten als Sammlung von Dokumenten oder in Graphen-Strukturen gespeichert.
Im Sprachgebrauch der Datenbankentwicklung und SQL-Programmierung werden grundlegende Konzepte relationaler Datenbanken verwendet, insbesondere: Tabelle, Spalte/Attribut, Beziehung, Constraint, Primärschllüssel, Fremdschlüssel, Datensicht.
Eine Tabelle ist eine benannte Menge von Spalten bzw. Attributen, die einem Objekt der Realität entspricht, und die Datensätze in Zeilen speichert. Man unterscheidet zwischen Tabellenstruktur (Tabellenname und Spaltennamen) und Tabelleninhalt (die Datensätze bzw. Zeilen). Für jede Tabelle wird eine Spalte als Primärschlüssel festgelegt, dann müssen die Werte dieser Spalte nicht leer und in der Tabelle einmalig sein. Primärschlüssel werden zur eindeutigen Identifizierung von Datensätzen verwendet.
Eine Beziehung zwischen zwei Tabellen entsteht durch Verwendung eines Fremdschlüssels in der einen Tabelle, der den Primärschlüssel einer anderen Tabelle referenziert. Fremdschlüssel werden zur Aufteilung von Daten auf mehrere Tabellen verwendet, um so eine redundanzfreie normalisierte Datenbankstruktur zu erreichen.
Constraints bzw. Integritätseinschränkungen legen fest, welche Werte in der Datenbank zulässig sind und sichern damit die Datenintegrität der Datenbank. Constraints sind Bedingungen, die die Datensätze für jeden gültigen Datenzustand erfüllen müssen und die ein DBMS bei jeder Update-Operation (Einfügen / Ändern / Löschen) überprüft. Die wichtigsten Constraints sind PRIMARY KEY (die Festlegung eines Primärschlüssels für eine Tabelle), FOREIGN KEY (die Festlegung einer Spalte als Fremdschlüssel, die JOIN-Beziehungen zwischen zwei Tabellen herstellt), NOT NULL (die Werte einer Spalte dürfen nicht leer sein), UNIQUE (die Werte einer Spalte müssen eindeutig sein).
Verletzung des Wertebereichs: Semester sollte Datentyp INT haben, hier wird ein String angegeben.
INSERT <ID:6, Name:Hauser, Vorname:Alex, Matrikelnr:1111, Semester:2, StudiengangID: "1"> IN STUDENT
Verletzung des Primärschlüssels: es gibt schon einen Datensatz mit Primärschlüssel 1
<ID:1, Name:Hauser, Vorname:Alex, Matrikelnr:1111, Semester:2, StudiengangID: 1>
Verletzung des Fremdschlüssels: es gibt keinen Studiengang mit ID 10
<ID:6, Name:Hauser, Vorname:Alex, Matrikelnr:1111, Semester:2, StudiengangID: 10>
Durch Angabe der passenden Constraints beim Erstellen der Datenbank sichert man die Datenbankintegrität. Das DBMS wird bei einer korrekt erstellten Datenbank durch Fehlermeldungen auf eine Verletzung der Datenintegrität hinweisen.
Eine View ist eine virtuelle Tabelle, genauer: eine Abfrage, die unter einem Alias-Namen gespeichert wird. Datensichten haben den Vorteil, dass sie die zugrundeliegende Komplexität von Tabellen verbergen und den Nutzern individuelle Sichten auf die Daten ermöglichen.
Im Lebenszyklus einer Datenbank erfolgt als erster Schritt das Erstellen der Datenbankstruktur mittels der SQL-Befehle CREATE, ALTER und DROP. Danach wird die Datenbank per Datenimport mit einem initialen Datenstand befüllt, dafür bieten Datenbankmanagementsysteme spezielle Import-Befehle, wie BULK INSERT in SQL Server. Die Datenbasis der Datenbank wird während ihres Einsatzes meist über eine (Web-) Anwendung aktualisiert, dort wird über Programmbibliotheken auf die Datenbank zugegriffen. Die SQL-Befehle INSERT, UPDATE und DELETE sind in die Programmiersprache des Datenbank-Clients eingebettet, dies kann PHP, Java, C#, Python oder eine andere Programmiersprache sein.
1-2 Kategorien von SQL-Befehlen: DML, DDL, DCL
| Top |
SQL-Befehle werden in die Kategorien DDL (data definition language), DML (data manipulation language) und DCL (data control language) unterteilt:
- DDL-Befehle dienen der Definition des Datenbankschemas (Datenbankobjekt anlegen: CREATE, löschen: DROP, ändern: ALTER).
- DML-Befehle dienen der Datenverwaltung, dazu gehört der lesende Zugriff (SELECT), die Datenmanipulation (Einfügen: INSERT, Löschen: DELETE, Ändern: UPDATE) und auch die Transaktionskontrolle (COMMIT, ROLLBACK).
- DCL-Befehle dienen der Rechteverwaltung: GRANT, REVOKE.
Einige SQL-Experten führen die Befehle für die Transaktionskontrolle in einer separaten Kategorie namens TCL (transaction control language).
Während der Lebenszyklus einer Datenbank mit dem Erstellen der Tabellen, Beziehungen und Views beginnt und dort zunächst die DDL-Befehle benötigt werden, ist es für den Einstieg einfacher, mit den DML-Befehlen anzufangen und das Befüllen und Abfragen einer vorhandenen Datenbank zu üben.
1-3 Aufbau eines SQL-Befehls
| Top |
Ein SQL-Befehl besteht aus Klauseln (Bestandteile), deren Reihenfolge im SQL-Standard fest vorgegeben ist. Dazu gehören: Name des Befehls (z.B. SELECT), Angabe der Datenbankobjekte, Hinweise zur Ausführung und Optionen. Jeder SQL-Befehl wird mit einem Semikolon (;) beendet.
Qualifizierte Namen
Für die Identifizierung eines Datenbankobjekts können qualifizierte Bezeichnungen mittels Punkt-Notation verwendet werden, z.B.
Tabelle.Spalte oder Datenbank.Tabelle.Spalte.
Groß-/Kleinschreibung
In SQL-Anweisungen werden die Schlüsselwörter (SELECT, FROM, WHERE, ...) per Konvention großgeschrieben, dies
dient der besseren Lesbarkeit. Der SQL-Standard unterscheidet jedoch nicht zwischen Groß-/Kleinschreibung, d.h.
select * from Student; wird genauso ausgeführt wie SELECT * FROM Student;.
SQL-Kommentare
Kommentare werden in SQL mit -- (zwei Bindestrichen) oder mit /* und */ angegeben.
SQL-Kommentare sind z.B. nützlich, wenn man größere SQL-Skripte für das Backup einer Datenbank erstellt.
SQL-Funktionen
SQL-Anweisungen können Funktionen enthalten, die Attributwerte umwandeln oder
neue Zahlenwerte über die Werte einer Spalte berechnen.
SQL-Funktionen können in unterschiedliche Kategorien unterteilt werden, dazu gehören:
Skalarfunktionen, mit deren Hilfe Attributwerte wie Strings oder numerische Werte verändert werden: LOWER, UPPER, MATCH, [...].
Aggregatfunktionen, die auf die Werte einer Spalte angewendet werden, z.B. MIN, MAX, SUM, AVG [...].
SQL-Beispiel
Das folgende Codefragment für die Abfrage der Elektrotechnik-Studenten aus unserer University-Datenbank
zeigt den typischen Aufbau und Schreibweise eines SQL-Befehls, unter Verwendung von Groß-/Kleinschreibung,
qualifizierten Bezeichnern für Tabellen und Spalten und abschließendem Semikolon.
Das Ergebnis der Abfrage ist eine Tabelle mit den angegebenen Spalten.
SELECT Student.Name, Student.Vorname, Student.Matrikelnr, Studiengang.Name AS StudiengangFROM University.Student, University.Studiengang -- Auswahl der TabellenWHERE Student.StudiengangID = Studiengang.ID -- JOIN-BedingungAND Studiengang.Name = 'Elektrotechnik'; -- Zeilenfilter
1-4 Der SQL-Standard
Die Datenbankmanagement-Systeme unterschiedlicher Anbieter implementieren alle den SQL-Standard ISO/IEC 9075, wobei es geringfügige Unterschiede bei der Umsetzung gibt, und anbieterspezifische Erweiterungen. Unterschiede gibt es insbesondere bei den DDL-Befehlen CREATE und ALTER, bei den DCL-Befehlen, und bei der Umsetzung der Datentypen. Der SQL-Standard legt z.B. eine Reihe von Datentypen für numerischen Werte, Zeichenketten, Datum und Uhrzeit etc. fest, die von den DBMS-Anbietern zum Teil auch unterschiedlich bezeichnet werden. Einige sind gleich, z.B. int als Datentyp für ganzzahlige Werte und varchar als Datentyp für Zeichenketten variabler Länge.
2 Vorbereitung: Ein DBMS installieren
| Top |
Um SQL praktisch zu lernen, benötigt man ein Datenbankmanagentsystem und eine darin erstellte Datenbank, an der man die SQL-Syntax ausprobieren kann. Zunächst: Was ist ein Datenbankmanagentsystem und welches sollte man für den Einstieg wählen?
Ein Datenbankmanagentsystem (DBMS) ist ein Softwaresystem, das die Erstellung und Wartung von Datenbanken
ermöglicht. Zu der Funktionalität eines DBMS gehört die Erstellung von Datenbanken,
d.h. die Festlegung der Datenbankstruktur durch Tabellen, Integritätseinschränkungen und Datensichten, die
Datenbank-Manipulation, d.h. das Einfügen, Ändern, Löschen der Daten, das effiziente Abfragen der Datenbanken,
die Gewährleistung von Datensicherheit, Datenschutz und Datenintegrität und noch einiges mehr.
Die heute eingesetzten DBMS unterstützen die Erstellung von Datenbanken über die grafische Benutzeroberfläche,
so dass man eine Datenbank auch erstellen kann, ohne SQL zu kennen.
Zu den häufig eingesetzten DBMS zählen Oracle DBMS, MS SQL Server, MySQL, MariaDB, PostgreSQL.
Für den Einstieg eignen sich die DBMS SQL Server mit SQL Server Management Studio als
Benutzeroberfläche und MySQL bzw. MariaDB mit phpMyAdmin als Benutzeroberfläche.
SQL Server ist stark in Microsoft-Anwendungen verankert und bietet den Vorteil, dass man ein
DBMS lernt, das in der Enterprise-Version auch in vielen Unternehmen eingesetzt wird.
MySQL bzw. MariaDB wird von Einsteigern bevorzugt, da die Datenbankverwaltung mit phpMyAdmin besonders intuitiv ist.
SQL Server
SQL Server ist ein kommerzielles DBMS von Microsoft, das in der Developer oder Express-Version für Lehre und privaten Gebrauch kostenlos verwendet werden kann. SQL Server wird in vielen Unternehmen eingesetzt und die Verwendung der Developer-Version ist ein guter Weg, um auf einem relativ einfachen Weg die Komplexität eines kommerziellen DBMS kennenzulernen. [SQLServer]
Die ersten Schritte bei der Erstellung einer Datenbank mit SQL Server Management Studio werden in dem folgenden Video gezeigt, insbesondere die Erstellung zweier Tabellen, die Festlegung von Primärschlüsseln mit Auto-Increment, die Verbindung der Tabellen durch Fremdschlüssel-Beziehungen.
MySQL / MariaDB
| Top |
MySQL ist ein Open Source-DBMS, das vor allem bei Webapplikationen als Backend eingesetzt wird. MariaDB ist 2009 als eine Abspaltung aus MySQL entstanden und wird in Open-Source-Projekten als Ersatz für MySQL eingesetzt. Da MySQL und MariaDB sich in der Kernfunktionalität nicht wesentlich unterscheiden, wird bei der Benennung oft MySQL verwendet, auch wenn MariaDB gemeint ist. Für das Datenbankmanagement von MySQL bzw. MariaDB stehen zwei Tools zur Verfügung: phpMyAdmin als webbasierte Benutzeroberfläche und MySQL Workbench als Desktopanwendung.
Wir verwenden für Lern- und Testzwecke das Programmpaket XAMPP, dies ist eine Zusammenstellung von Programmen und Sprachen für Datenbank- und Webentwicklung. XAMPP enthält neben dem Apache Webserver auch MariaDB, PHP, Tomcat (...) und wird rein für Entwicklung und aus Sicherheitsgründen nicht im produktiven Betrieb eingesetzt. XAMPP sollte am besten im Ordner C:\XAMPP installiert werden. Es reicht, bei der Installation die Komponenten Apache Webserver, MySQL und PHP auszuwählen, die Installation selber dauert weniger als 10 Minuten.
XAMPP Control Panel
Webserver (Apache) und DBMS (mySQL) starten / stoppen / konfigurieren
phpMyAdmin wird als Teil von XAMPP automatisch mit installiert und wird aufgerufen, indem man im XAMPP Control Panel (xampp-control.exe) auf die Schaltfläche "Admin" neben MySQL klickt. Daraufhin öffnet sich die Benutzeroberfläche von phpMyAdmin als Webseite mit der URL http://localhost/phpmyadmin in Ihrem Default-Browser.
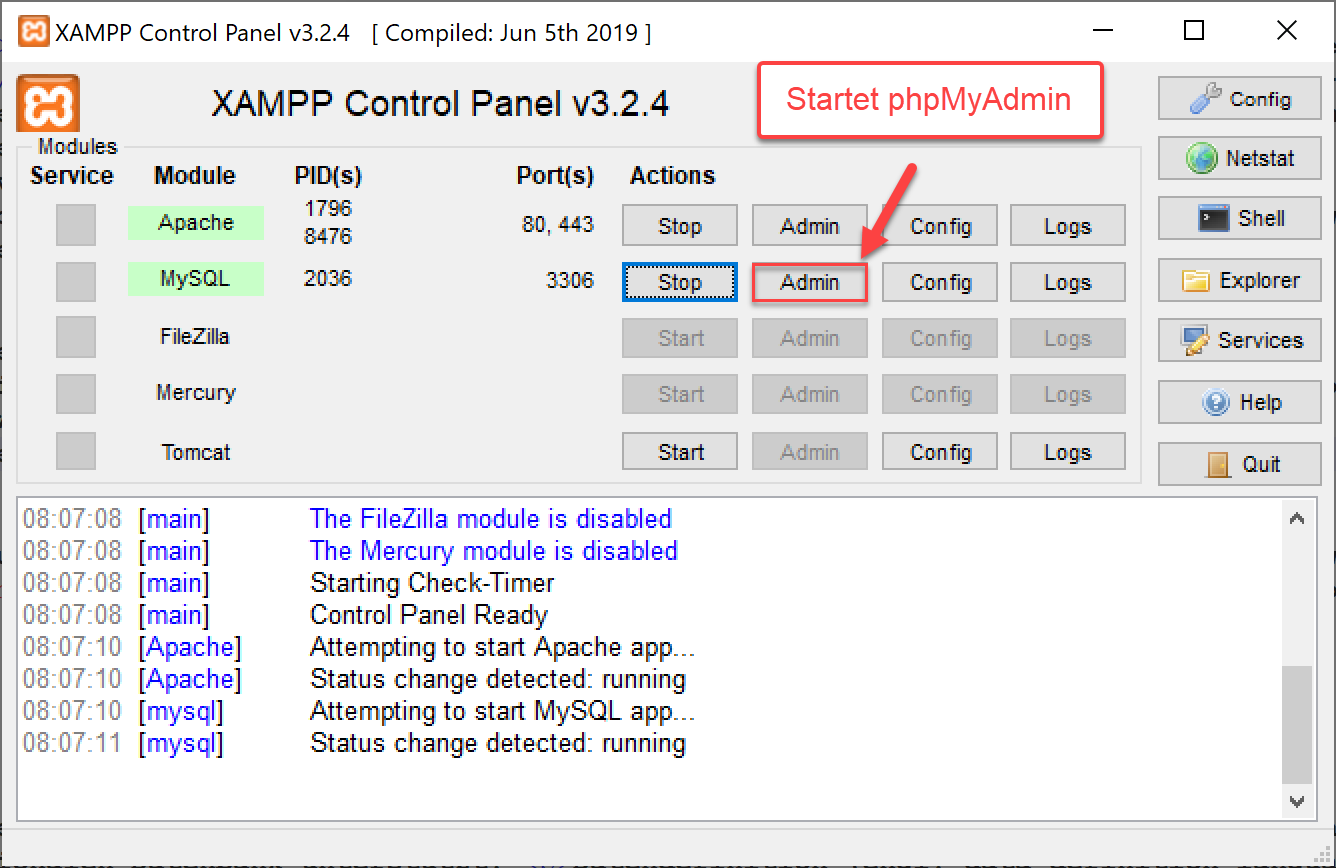
phpMyAdmin
Datenbanken verwalten und abfragen
Die komplette University-Datenbank für das Tutorial kann mit Hilfe der phpMyAdmin-Benutzeroberfläche angelegt werden, auch ohne SQL im Detail zu kennen. Grundlegende Konzepte über Datenbanken (Tabellen / Beziehungen, Datentypen, Integritätseinschränkungen) sollten allerdings bekannt sein.
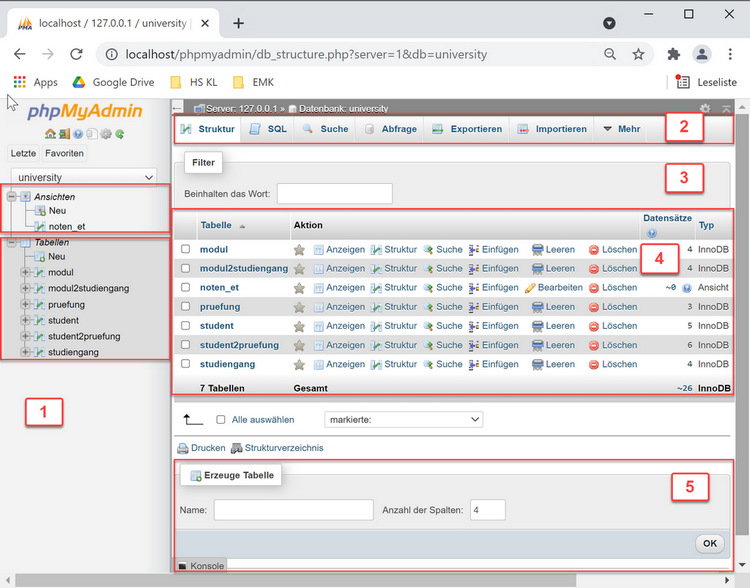
Die Verwendung von phpMyAdmin für die Erstellung, Verwaltung und Abfrage von Datenbanken wird in dem Artikel Erste Schritte mit phpMyAdmin beschrieben.
3 Beispiel-Datenbank University
| Top |
Als Beispiel dient eine Datenbank mit dem Arbeitsnamen "University", die Daten über Studenten, Module und Prüfungen in einer Universitätsumgebung verwaltet.
3-1 Anforderungen
Die Anforderungen an die Strukur der Daten sind wie folgt:
- Ein Studiengang hat einen Namen und eine Studiengang-Art ("Bachelor" / "Master").
- Ein Student hat die Attribute Name, Vorname, Matrikelnummer, Semester und ist in genau einen Studiengang eingeschrieben.
- Ein Modul hat die Attribute Name, Semester, CP, SWS und ist einem Studiengang zugeordnet, kann aber auch in anderen Studiengängen verwendet werden.
- Zu einem Modul gibt es Prüfungen. Zu einer Prüfung wird das zugehörige Modul, das Jahr, das Semester und der Dozent erfasst.
- Die Noten eines Studenten in einer bestimmten Prüfung werden in einer Zuordnungstabelle Student2Prüfung erfasst.
Die Datenbank soll die Noten der Studierenden über mehrere Jahre hinweg speichern und Anfragen ermöglichen wie: "Gebe die Noten aller Studierenden im Studiengang Elektrotechnik im Jahr 2022 aus, gruppiert nach Prüfungen und aufsteigend sortiert nach Note." "Gebe alle Noten eines bestimmten Studierenden aus." "Gebe die Studierenden zurück, deren Noten in einem bestimmten Fach sehr gut sind."
3-2 Entity-Relationship-Diagramm
| Top |
Im Rahmen des Datenbankentwurfs wird aus den Anforderungen ein Entity-Relationship-Diagramm bzw. ER-Diagramm erstellt. Ein Entity-Relationship-Diagramm ist ein konzeptionelles Modell zur formalisierten Darstellung der Datensicht im Rahmen eines Datenbankentwurfs. Das ER-Diagramm beschreibt Daten als Entitäten mit Eigenschaften, zwischen denen es Beziehungen gibt. Entitäten repräsentieren real existierende Objekte, z.B. Student, Studiengang, Modul.
Die meisten DBMS bieten das Erstellen von ER-Diagrammen über einen Designer als Funktionalität an, teilweise auch mit der Möglichkeit, aus dem ER-Modell direkt die Tabellen zu erzeugen, oder umgekehrt aus schon erstellten Tabellen ein ER-Modell.
Datenbankschema
Das Datenbankschema beschreibt die Struktur der Datenbank, siehe ER-Diagramm. Die Datenbank enthält vier Tabellen, die Objekten bzw. Entitäten entsprechen: Studiengang, Modul, Student und Prüfung, und zwei Tabellen, die viele-zu-viele Beziehungen zwischen den Entitäten entsprechen: Modul2Studiengang und Student2Prüfung.
Jede Tabelle hat eine Spalte ID, die den eindeutigen Primärschlüssel der Datensätze speichert. Über diesen Primärschlüssel kann ein Datensatz von anderen Tabellen aus referenziert werden. Die Tabellen Student und Modul haben jeweils eine Spalte StudiengangID, die ein Fremdschlüssel auf die Tabelle Studiengang ist.
Datenbankinhalt ("Snapshot")
Der initiale Datenbankinhalt besteht aus vier Studiengängen, fünf Studenten, vier Modulen, fünf Prüfungen und den entsprechenden Zuordnungen, die über Fremdschlüsselbeziehungen abgebildet werden.
Die Note eines Studenten in einer Prüfung wird in der Tabelle Student2Prüfung gespeichert. Der Eintrag <1, 3, 1.7 > in dieser Tabelle bedeutet, dass der Student mit ID 1 in der Prüfung mit ID 3 die Note 1.7 erzielt hat.
Entity-Relationship-Diagramm
Das ER-Diagramm der Datenbank zeigt die Tabellen und ihre Beziehungen.
- Studiengang enthält die Daten der Studiengänge.
- Modul enthält die Liste der Module.
- Student wird die Daten der Studenten enthalten. Die Matrikelnummer muss eindeutig sein, daher erhält die Spalte die UNIQUE-Integritätseinschränkung
- Prüfung wird Daten der Prüfungen enthalten.
Die Struktur (Tabellen, Beziehungen und Constraints) der University-Datenbank kann wie in Abschnitt 5-1 beschrieben mit Hilfe eines Skriptes zum Erzeugen der University-Datenbank erstellt werden.
4 DML-Befehle: SELECT, INSERT, UPDATE, DELETE
| Top |
DML-Befehle dienen der Datenverwaltung, dazu gehört der lesende Zugriff (SELECT) und die Datenmanipulation (Einfügen/INSERT, Löschen/DELETE, Ändern/UPDATE)
4-1 SELECT: Daten abfragen
| Top |
Suchanfragen in einer relationalen Datenbank werden mit Hilfe des SELECT-Befehls ausgeführt. Der SELECT-Befehl bietet die Funktionalität, Datensätze einer einzelnen Tabelle, mehrerer Tabellen oder auch Views abzufragen, und liefert stets eine tabellarische Ergebnisliste zurück. Die Datensätze können optional sortiert und gruppiert werden. Suchanfragen verändern weder Datenbankschema noch Datenbankzustand, sie liefern lediglich eine Menge von Datensätzen zurück, die den Suchkriterien entsprechen. D.h. mit dem SELECT-Befehl kann man nichts kaputtmachen. Eine ungünstig formulierte SELECT-Anfrage kann jedoch länger dauern.
Syntax
Die allgemeine Syntax des SQL-Befehls besteht aus zwei bis fünf Teilen, von denen nur die ersten zwei verpflichtend sind:
(1) SELECT-Schlüsselwort, gefolgt von den auszuwählenden Spalten (kommagetrennt),
(2) FROM-Schlüsselwort, gefolgt von den auszuwählenden Tabellen (kommagetrennt),
(3) WHERE-Schlüsselwort, gefolgt von den Bedingungen für die Zeilenfilter,
(4) ORDER BY-Schlüsselwort, gefolgt von den Sortierspalten,
(5) GROUP BY-Schlüsselwort, gefolgt von den Gruppierspalten.
SELECT [DISTINCT] Spalte1 AS Alias1, Spalte2 AS Alias2, [...]FROM Tabelle1, Tabelle2, [...]/* Optional: WHERE-Klausel */WHERE Bedingungen/* Optional: Sortierklausel */ORDER BY Spalte1, Spalte2 [...];/* Optional: Gruppierklausel */GROUP BY Spalte1, Spalte2 [...];
Wirkung
SELECT wählt aus den Tabellen Zeilen aus, die die nach WHERE angegebene Bedingungen erfüllen und zeigt nur Spalten an, die der Spaltenliste entsprechen. Eine Suchabfrage über mehrere Tabellen muss mit entsprechenden JOIN-Bedingungen versehen werden. Die Spaltennamen und Tabellennamen können Alias-Namen erhalten, dafür wird das Schlüsselwort AS verwendet, z.B. Studiengang AS Stg, Studiengang.Name AS StgName.
SELECT-1: Inhalt einer Tabelle ausgeben
| Top |
Die einfachste SELECT-Anweisung ist die Ausgabe des kompletten Inhaltes einer Tabelle. Die Angabe der Spalten in der SELECT-Anweisung kann weggelassen werden, wenn stattdessen ein * (asterisk) als Wildcard angegeben wird. In diesem Fall werden alle Attribute / Spalten ausgegeben.
Tabelle Studiengang
SQL-Abfrage:
Gebe alle Studiengänge aus.
SELECT * FROM Studiengang;
Ergebnis-Tabelle:
Inhalt der Tabelle Studiengang
| ID | Name | Art |
|---|---|---|
| 1 | Elektrotechnik | Master |
| 2 | Elektrotechnik | Bachelor |
| 3 | Maschinenbau | Master |
| 4 | Maschinenbau | Bachelor |
Tabelle Student
SQL-Abfrage:
Gebe alle Studenten aus.
SELECT * FROM Student;
Ergebnis-Tabelle:
Inhalt der Tabelle Student
| ID | Name | Vorname | Matrikelnr | StudiengangID | Semester |
|---|---|---|---|---|---|
| 1 | Fischer | Jan | 12346 | 2 | 2 |
| 2 | Lang | Elke | 12347 | 1 | 2 |
| 3 | Weber | Michael | 12348 | 1 | 1 |
| 4 | Schuster | Thomas | 12349 | 2 | 1 |
| 5 | Muster | Max | 12345 | 3 | 1 |
SELECT-2: Zeilen und Spalten auswählen
| Top |
Die Ergebniszeilen einer SELECT-Anweisung werden mit der WHERE-Klausel gefiltert, gefolgt von Bedingungen, die mit logischen Operatoren (AND, OR, NOT) verknüpft werden. Nach dem Schlüsselwort SELECT können die Spalten /Attribute angegeben werden, die für die Ergebnistabelle berücksicht werden sollen, als kommagetrennte Liste, in der Reihenfolge, wie sie benötigt werden.
Zeilen-Filter
SQL-Abfrage
Gebe eine Liste aller Studenten aus dem ersten Semester zurück, deren Name die Zeichenkette 'er' enthält. Für den Zeilenfilter wird das Schlüsselwort LIKE und die Wildcard % verwendet. Für den Spaltenfilter wird die Wildcard * verwendet, es werden also alle Spalten ausgegeben.
SELECT * FROM StudentWHERE Semester = 1 AND Name LIKE '%er%';
Ergebnis-Tabelle
| ID | Name | Vorname | Matrikelnr | StudiengangID | Semester |
|---|---|---|---|---|---|
| 3 | Weber | Michael | 12348 | 1 | 1 |
| 4 | Schuster | Thomas | 12349 | 2 | 1 |
| 5 | Muster | Max | 12345 | 3 | 1 |
Zeilen- und Spalten-Filter
SQL-Abfrage
Gebe eine Liste aller Studenten zurück, die im ersten Semester sind, oder deren Name die Zeichenkette 'er' enthält, jedoch nur die angegebenen Spalten.
SELECT Name, Vorname, Matrikelnr FROM StudentWHERE Semester = 1 OR Name LIKE '%er%';
Ergebnis-Tabelle
| Name | Vorname | Matrikelnr |
|---|---|---|
| Fischer | Jan | 12346 |
| Weber | Michael | 12348 |
| Schuster | Thomas | 12349 |
| Muster | Max | 12345 |
SELECT-3: Sortieren und Duplikate entfernen
| Top |
Die Sortierung der Ergebniszeilen einer SQL-Abfrage erfolgt mittels der ORDER BY-Klausel. Nach dem Schlüsselwort ORDER BY werden die Spalten angegegen, nach denen sortiert werden muss, ggf. gefolgt von den Zusätzen ASC (aufsteigend sortieren) oder DESC (absteigend sortieren).
Das Schlüsselwort DISTINCT wird verwendet, um Duplikate aus den Ergebniszeilen einer SQL-Abfrage zu entfernen.
Sortieren: ORDER BY
SQL-Abfrage
Gebe Name, Vorname und Matrikelnummer aller Studenten zurück, die im ersten Semester studieren, sortiert nach Name und Vorname.
SELECT Name, Vorname, Matrikelnr FROM StudentWHERE Semester = 1ORDER BY Name ASC, Vorname ASC
Ergebnis-Tabelle
| Name | Vorname | Matrikelnr |
|---|---|---|
| Muster | Max | 12345 |
| Schuster | Thomas | 12349 |
| Weber | Michael | 12348 |
Duplikate entfernen: DISTINCT
SQL-Abfrage
Gebe die Namen der Studiengänge aus, die in der Tabelle Studiengang enthalten sind, ohne Duplikate.
SELECT DISTINCT Name FROM Studiengang;
Die Ergebnis-Tabelle enthält lediglich die Namen der Studiengänge Elektrotechnik und Maschinenbau. Ohne das Schlüsselwort DISTINCT wäre Elektrotechnik zweimal enthalten gewesen, und Maschinenbau zweimal enthalten, da der SELECT-Befehl einfach die Spalte Name für alle Datensätze geliefert hätte.
Ergebnis-Tabelle
| Name |
|---|
| Elektrotechnik |
| Maschinenbau |
SELECT-4: Kartesisches Produkt
| Top |
Das Ergebnis der Abfrage SELECT * FROM Student, Studiengang; ist das kartesische Produkt oder Kreuzprodukt der beiden Tabellen Student und Studiengang, also eine Tabelle, deren Inhalt jeweils die Menge der "Studenten" bzw. der "Studiengänge" ist. Es wird jeder Datensatz der Tabelle Student mit jedem Datensatz der Tabelle Studiengang kombiniert. Die Ergebnistabelle wird insgesamt 5*4 Datensätze enthalten, da wir 5 Studenten- und 4 Studiengang-Datensätze haben. Wir geben hier jedoch nur die ersten 8 Datensätze aus, dies erreicht man in MariaDB durch Angabe der LIMIT-Klausel: SELECT * FROM Student, Studiengang LIMIT 8;
| ID | Name | Vorname | Matrikelnr | StudiengangID | Semester | STGID | Studiengang | Art |
|---|---|---|---|---|---|---|---|---|
| 1 | Fischer | Jan | 12346 | 2 | 2 | 1 | Elektrotechnik | Master |
| 1 | Fischer | Jan | 12346 | 2 | 2 | 2 | Elektrotechnik | Bachelor |
| 1 | Fischer | Jan | 12346 | 2 | 2 | 3 | Maschinenbau | Master |
| 1 | Fischer | Jan | 12346 | 2 | 2 | 4 | Maschinenbau | Bachelor |
| 2 | Lang | Elke | 12347 | 1 | 2 | 1 | Elektrotechnik | Master |
| 2 | Lang | Elke | 12347 | 1 | 2 | 2 | Elektrotechnik | Bachelor |
| 2 | Lang | Elke | 12347 | 1 | 2 | 3 | Maschinenbau | Master |
| 2 | Lang | Elke | 12347 | 1 | 2 | 4 | Maschinenbau | Bachelor |
Die Ausgabe des kartesischen Produktes zweier Tabellen ist meist unerwünscht. Das Ziel einer SELECT-Abfrage über mehrere Tabellen ist stets, aus den verschiedenen Tabellen die zueinander passenden Datensätze zu filtern, hier: zu jedem Studenten nur denjenigen Studiengang, in dem er zufolge der Fremdschlüssel-Spalte StudiengangID eingeschrieben ist. Dafür muss die SELECT-Abfrage um eine JOIN-Klausel erweitert werden, die auch direkt als Bedingung (hier: Student.StudiengangID = Studiengang.ID) in die WHERE-Klausel eingefügt werden kann.
SELECT-5: Mehrere Tabellen abfragen mit JOIN
| Top |
Eine SELECT-Anweisung über mehrere Tabellen muss die Beziehungen zwischen den Tabellen stets mit passenden JOIN-Bedingungen abbilden. Die JOIN-Bedingungen können entweder in der WHERE-Klausel enthalten sein, oder sie können mit Hilfe einer expliziten JOIN-Klausel abgebildet werden.
Syntax (JOIN-Klausel)
SELECT Attributliste FROM TabelleINNER JOIN Tabelle2 ON Join-BedingungWHERE Auswahl-Bedingung
- Ein INNER JOIN liefert nur diejenigen Datensätze, die passende Werte in beiden Tabellen haben.
- Ein LEFT JOIN liefert alle Datensätze der linken Tabelle und nur diejenigen Datensätze der rechten Tabelle, die der JOIN-Bedingung nach passen.
- Ein RIGHT JOIN liefert alle Datensätze der rechten Tabelle und nur diejenigen Datensätze der linken Tabelle, die der JOIN-Bedingung nach passen.
- Ein FULL OUTER JOIN liefert alle Datensätze beider Tabellen, wobei bei den Datensätzen ohne entsprechende Werte NULL eingetragen wird.
Beispiel: INNER JOIN
Als Beispiel soll eine Liste aller Studenten zurückgegeben werden, mit Angabe von Matrikelnummer, Name, Vorname der Studierenden sowie Name und Art des Studiengangs. Dafür müssen die Daten aus zwei Tabellen ausgelesen werden, Student und Studiengang, und über die Fremdschlüssel-Beziehung die zueinander passenden Datensätze gefiltert werden. Über die JOIN-Bedingung Student.StudiengangID= Studiengang.ID finden wir zu jedem Studenten Name und Art des Studiengangs. Die Spalten Student.StudiengangID und Studiengang.ID werden hier nur für die JOIN-Bedingung verwendet und nicht ausgegeben, da sie für den Nutzer der Anwendung nicht relevant sind.
JOIN (Implizit)
SQL-Abfrage
Gebe eine Liste aller Studenten zurück, mit Angabe von Matrikelnummer, Name, Vorname und Art des Studiengangs.
SELECT Matrikelnr, Student.Name, Vorname,Studiengang.Name AS Studiengang, ArtFROM Student, StudiengangWHERE Student.StudiengangID= Studiengang.ID;
Ergebnis-Tabelle
| Matrikelnr | Name | Vorname | Studiengang | Art |
|---|---|---|---|---|
| 12346 | Fischer | Jan | Elektrotechnik | Bachelor |
| 12347 | Lang | Elke | Elektrotechnik | Master |
| 12348 | Weber | Michael | Elektrotechnik | Master |
| 12349 | Schuster | Thomas | Elektrotechnik | Bachelor |
| 12345 | Muster | Max | Maschinenbau | Master |
JOIN (Explizit)
SQL-Abfrage
Gebe eine Liste aller Studenten zurück, mit Angabe von Matrikelnummer, Name, Vorname und Art des Studiengangs.
SELECT Matrikelnr, Student.Name, Vorname,Studiengang.Name AS Studiengang, ArtFROM Student INNER JOIN StudiengangON Student.StudiengangID= Studiengang.ID;
Ergebnis-Tabelle
| Matrikelnr | Name | Vorname | Studiengang | Art |
|---|---|---|---|---|
| 12346 | Fischer | Jan | Elektrotechnik | Bachelor |
| 12347 | Lang | Elke | Elektrotechnik | Master |
| 12348 | Weber | Michael | Elektrotechnik | Master |
| 12349 | Schuster | Thomas | Elektrotechnik | Bachelor |
| 12345 | Muster | Max | Maschinenbau | Master |
Beispiel: LEFT JOIN
Gebe eine Liste aller Studiengänge mit den dazugehörenden Studenten zurück, mit Angabe von Matrikelnummer, Name, Vorname, sortiert nach Name des Studiengangs und Name und Vorname des Studierenden. Es sollen auch diejenigen Studiengänge ausgegeben werden, die keine Studierenden enthalten.
SELECT Studiengang.Name AS StgName, Art,Matrikelnr, Student.Name, VornameFROM StudiengangLEFT JOIN Student ON Student.StudiengangID= Studiengang.IDORDER BY StgName, Name, Vorname ASC;
SELECT-6: Unterabfragen
| Top |
Um eine Suchanfrage auszuführen, benötigt man häufig Werte, die man nicht direkt kennt, sondern vorher durch andere Anfragen herausfinden muss. Unterabfragen sind SELECT-Anweisungen, die nur eingebettet in eine andere SQL-Anweisung ausgeführt werden. Diese andere SQL-Anweisung kann ein SELECT sein, oder ein INSERT, UPDATE oder DELETE. Es sollen z.B. alle Studenten gefunden werden, die eine bestimmte Prüfung geschrieben haben, deren Namen man kennt. Um diese Suchanfrage stellen zu können, muss man zunächst mittels Unterabfrage die ID der Prüfung herausfinden. Für diesen Fall hat SQL vorgesehen, dass man eine SELECT-Anweisung in eine andere SELECT-Anweisung einbetten kann.
Beispiel
Gebe eine Liste der Studierenden zurück, die die Prüfung "Datenbanken" im Jahr 2019 geschrieben haben, mit Angabe des Modulnamens, des Jahres und der Note. Dieser SELECT verknüpft 4 Tabellen miteinander. Die ID der Prüfung wird über eine Unterabfrage herausgefunden, die die Tabellen Prüfung und Modul verknüpft.
SQL-Abfrage
SELECT S.Name, S.Vorname, S.Matrikelnr, M.Name AS Modulname, P.Jahr, SP.NoteFROM Student AS S, Modul AS M, Prüfung As P, Student2Prüfung As SPWHERE (M.ID = P.ModulID) -- JOIN Modul - PrüfungAND (SP.StudentID = S.ID) -- JOIN Student2Prüfung - StudentAND (SP.PrüfungID = P.ID) -- JOIN Student2Prüfung - PrüfungAND SP.PrüfungID = -- Auswahlbedingung: PrüfungID(SELECT P.ID FROM Prüfung AS P, Modul AS M -- UnterabfrageWHERE P.ModulID = M.IDAND M.Name LIKE 'Datenbank%' AND P.Jahr = 2019)
Ergebnis-Tabelle
| Name | Vorname | Matrikelnr | Modulname | Jahr | Note |
|---|---|---|---|---|---|
| Lang | Elke | 12347 | Datenbanken | 2019 | 1.3 |
| Weber | Michael | 12348 | Datenbanken | 2019 | 3.7 |
| Schuster | Thomas | 12349 | Datenbanken | 2019 | 2 |
SELECT-7: Gruppieren mit GROUP BY-Klausel
| Top |
Die GROUP BY-Klausel wird verwendet, um Zeilen der Ergebnisliste zu gruppieren. Die Gruppierung geschieht in Zusammenhang mit einer Aggregatsfunktion (z.B. COUNT oder SUM), die für die gruppierten Werte einen neuen Einzelwert berechnet.
Syntax
Das Schlüsselwort GROUP BY steht in der Reihenfolge nach der WHERE-Klausel und wird gefolgt von einer Liste von Attributen / Spalten, nach denen gruppiert werden soll, und einer Aggregatsfunktion über eine weitere Spalte. Wichtig: Die Gruppierspalten müssen auch als Attribute nach SELECT angegeben werden
SELECT Gruppierspalte1, Gruppierspalte2, Aggregation [...]FROM Tabelle1, Tabelle2, [...]WHERE BedingungenGROUP BY Gruppierspalte1, Gruppierspalte2 [...]
GROUP BY
SQL-Abfrage
Gebe Anzahl der Studenten aus, gruppiert nach Name und Art des Studiengangs. D.h. wie viele studieren Elektrotechnik Bachelor, wie viele Maschinenbau Bachelor etc.
SELECT ST.Name AS Studiengang, ST.Art AS Art,COUNT(S.ID) AS AnzahlFROM Student AS S, Studiengang AS STWHERE S.StudiengangID = ST.IDGROUP BY ST.Name, ST.Art;
Ergebnis-Tabelle
| Studiengang | Art | Anzahl |
|---|---|---|
| Elektrotechnik | Bachelor | 2 |
| Elektrotechnik | Master | 2 |
| Maschinenbau | Master | 1 |
GROUP BY mit Having
SQL-Abfrage
Gebe Anzahl der Studenten aus, gruppiert nach Art des Studiengangs, jedoch nur für diejenigen Studiengangs-Arten, die mehr als zwei Studenten haben.
SELECT ST.Art AS StudiengangArtCOUNT(S.ID) AS AnzahlFROM Student AS S, Studiengang AS STWHERE S.StudiengangID = ST.IDGROUP BY ST.ArtHAVING Count(S.ID) >= 2;
Ergebnis-Tabelle
| Studiengang-Art | Anzahl |
|---|---|
| Bachelor | 2 |
| Master | 3 |
4-2 INSERT: Datensätze einfügen
| Top |
INSERT bzw. INSERT INTO ist die Anweisung zum Einfügen neuer Datensätze in eine Tabelle.
Die allgemeine Syntax des INSERT-Befehls besteht aus zwei Teilen:
(1) dem Schlüsselwort INSERT INTO, gefolgt von dem Namen der Tabelle, und in runden Klammern eine kommagetrennte Liste von Spaltennamen,
(2) dem Schlüsselwort VALUES, gefolgt von den einzufügenden Datensätzen, als Kkommagetrennte Liste.
Die Werte für einen Datensatz müssen ebenfalls als kommagetrennte Liste in runde Klammern gesetzt werden.
Syntax
INSERT INTO Tabelle(Spalte1, Spalte2, ...)VALUES (Wert11, Wert12, ...), /* Datensatz 1 */(Wert21, Wert22, ...), /* Datensatz 2 */(Wert31, Wert32, ...); /* Datensatz 3 */
Wirkung
INSERT schreibt in die angegebene Tabelle und die angegebenen Spalten/Attribute der Tabelle die angegebenen Datensätze, wobei Anzahl, Reihenfolge und Datentyp der Werte eines Datensatzes mit denen der Attribute übereinstimmen muss. Die Attributsliste kann weggelassen werden. Wenn jedoch keine Attribute angegeben werden, müssen in der Werteliste die Werte für alle Attribute der Tabelle in der richtigen Reihenfolge angegeben werden. Falls Integritätseinschränkungen verletzt werden, wird der Datensatz nicht eingefügt und es wird eine Fehlermeldung angezeigt.
INSERT-1: Einfügen mit Angabe der Spaltennamen
Füge den Datensatz Bart Simpson in die Tabelle Student ein. Die Spaltennamen werden explizit angegeben, d.h. als Name wird Bart eingetragen, als Vorname Simpson etc.
INSERT INTO Student (Name, Vorname, Matrikelnr, StudiengangID, Semester)VALUES('Simpson', 'Bart', 12349, 3, 3),('Simpson', 'Marge', 12350, 3, 4);
INSERT-2: Einfügen ohne Angabe der Spaltennamen
Füge den Datensatz Bart Simpson in die Tabelle Student ein. Die Spaltennamen werden nicht angegeben, sondern der erste Wert wird in die erste Spalte der Tabelle eingetragen, der zweite Wert in die zweite Spalte der Tabelle etc.
INSERT INTO StudentVALUES('Simpson', 'Bart', 12349, 3, 3),('Simpson', 'Marge', 12350, 3, 4);
In MySQL geschieht das mit dem Schlüsselwort AUTO_INCREMENT. Die Eigenschaft kann entweder direkt beim Erstellen der Tabelle oder nachträglich mittels ALTER-Befehl eingetragen werden.
ALTER TABLE Student /* MySQL */ MODIFY ID int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=1;In SQL Server wird das Autoinkrement einer Spalte mit der IDENTITY-Klausel erreicht: IDENTITY(1,1) bedeutet, dass bei Einfügen durch das DBMS automatisch ein neuer Schlüssel generiert wird, der den Schlüssel des zuletzt eingefügten Datensatzes um 1 inkrementiert.
[ID] [int] IDENTITY(1,1) NOT NULL
4-3 UPDATE: Datensätze ändern
UPDATE ist die Anweisung zum Ändern von Datensätzen aus einer Tabelle.
Syntax
UPDATE TabelleSET Attribut1=Wert1, Attribut2=Wert2,…Attributn=WertnWHERE Bedingungen;
Wirkung
UPDATE aktualisiert in der angeführten Tabelle diejenigen Datensätze, die die angegebenen Bedingungen erfüllen. Die SET-Klausel enthält kommagetrennte Zuweisungen der Form Attribut = Wert. Die WHERE-Klausel ist grundsätzlich optional, sollte aber trotzdem nicht vergessen werden. Wird sie weggelassen, so werden alle Datensätze der Tabelle aktualisiert, dies ist meist nicht die Absicht.
UPDATE-1: Ändern eines einzelnen Datensatzes
Ändere Namen des Studenten mit Matrikelnummer 12345 in 'Muster', und seinen Vornamen in 'Horst'.
UPDATE StudentSET Name = 'Muster', Vorname = 'Horst'WHERE Matrikelnr = 12345;
UPDATE-2: Ändern aller Datensätze einer Tabelle
Setze das Semester aller Studenten die im 6ten Semester auf das 7te Semester.
UPDATE Student SET Semester = 7WHERE Semester = 6;
4-4 DELETE: Datensätze löschen
DELETE bzw. DELETE FROM ist die Anweisung zum Löschen von Datensätzen aus einer Tabelle.
Syntax
Nach dem Schlüsselwort DELETE FROM wird die Tabelle angegeben, aus der gelöscht werden soll, gefolgt von einer WHERE-Klausel mit Bedingungen, die die Anzahl der zu löschenden Datenssätze einschränken.
DELETE FROM TabelleWHERE Bedingungen;
Wirkung
DELETE löscht aus der angeführten Tabelle alle Datensätze, die die Bedingungen erfüllen. Die WHERE-Klausel ist optional. Wird sie weggelassen, so wird der komplette Inhalt der Tabelle gelöscht.
Beispiel
Lösche die Studenten, deren Name Mustermann ist.
DELETE FROM StudentWHERE Name = 'Mustermann';
5 DDL-Befehle
| Top |
Die DDL-Befehle CREATE, DROP, ALTER werden verwendet, um Datenbankobjekte bzw. Strukturen zu erstellen, zu ändern oder zu löschen. Ein Datenbankobjekt ist: die Datenbank selber, ein Schema, eine Tabelle, eine View / Sicht oder ein Constraint (Primärschlüssel, Fremdschlüssel, UNIQUE-Constraint, NOT NULL-Constraint).
5-1 CREATE: Strukturen anlegen
Mit den CREATE-Befehlen erzeugt man die Struktur von Datenbanken, d.h. die Datenbank selber, Tabellen, Sichten, Datenbank-Constraints etc. Die CREATE-Befehle sind nicht durchgehend standardisiert, so dass es hier DBMS-abhängige Besonderheiten gibt, und ein wichtiger Unterschied ist die Beachtung von Groß- und Kleinschreibung.
- lower_case_table_names = 0: Tabellennamen werden wie angegeben gespeichert und bei Vergleichen wird die Groß-/Kleinschreibung beachtet.
- lower_case_table_names = 1: Tabellennamen werden in Kleinbuchstaben auf der Festplatte gespeichert und bei Vergleichen wird die Groß-/Kleinschreibung nicht beachtet.
- lower_case_table_names = 2: Tabellennamen werden wie angegeben gespeichert, aber in Kleinbuchstaben verglichen.
Datenbank erstellen: CREATE DATABASE
Der CREATE DATABASE-Befehl erzeugt eine neue leere Datenbank mit Default-Optionen. Dabei wird die physische Datenbankdatei in dem Zugriffspfad des DBMS angelegt. Gleichzeitig mit der Datenbank wird eine zugehörige Transaktions-Log-Datei angelegt. Um anschließend Tabellen in der Datenbank zu erstellen, muss sie mit USE Datenbank ausgewählt werden.
Syntax
CREATE DATABASE [IF NOT EXISTS] Datenbank;USE Datenbank;
Falls eine Datenbank mit dem angegebenen Namen schon existiert, wird eine Fehlermeldung ausgegeben. Diese Fehlermeldung kann mit Hilfe der optionalen Klausel IF NOT EXISTS vermieden werden.
Beispiel: University-Datenbank erstellen
CREATE DATABASE University; USE University;
Tabelle erstellen: CREATE TABLE
| Top |
CREATE TABLE ist der Befehl zum Erstellen einer neuen Tabelle.
Syntax
Nach dem Schlüsselwort CREATE TABLE werden Tabellenname und danach in runden Klammern und kommagetrennt die Attribute/Spalten und optional auch Constraints (Primärschlüssel, Fremdschlüssel, NOT NULL) angegeben. Tabellen- und Spaltennamen, die Leerzeichen enthalten, werden in eckige Klammern gesetzt.
CREATE TABLE Tabelle1 (Spalte1 datentyp1,Spalte2 datentyp2,[... weitere Spalten],PRIMARY KEY (Spalte1),CONSTRAINT FK_NAME FOREIGN KEY (FK) REFERENCES Tabelle2 (PK) );
Wirkung
Bei Ausführen des Befehls wird die Struktur für die neue Tabelle angelegt, d.h. die Spalten der Tabelle mit den passenden Datentypen und Constraints, ggf. auch schon Beziehungen zu anderen Tabellen. Die FOREIGN KEY-Klausel ist hier optional und kann auch nachträglich per ALTER TABLE-Befehl hinzugefügt werden. Über die FOREIGN KEY-Klausel kann auch festgelegt werden, welche Aktionen im Falle einer Integritätsverletzung durch Update-Operationen erfolgen sollen. Drei Optionen sind möglich: SET DEFAULT, SET NULL oder CASCADE. SET DEFAULT bedeutet, dass bei Löschen eines Datensatzes der referenzierten Tabelle (z.B. Studiengang) eine Fehlermeldung erfolgt, wenn es in der referenzierenden Tabelle (hier: Student) noch Datensätze gibt, die sich auf den zu löschenden Eintrag beziehen.
Struktur einer Datenbank anlegen
Beim Anlegen einer neuen Datenbank hat man in der Regel als Erstes auf Basis der Anforderungen ein ER-Diagramm mit den benötigten Tabellen und Beziehungen entworfen. Als nächstes müssen die Tabellen in der Datenbank erstellt werden, dabei ist die Reihenfolge zu beachten: zuerst die referenzierten Tabellen, danach die referenzierenden Tabellen. Bei der University-Datenbank ist die korrekte Reihenfolge: Studiengang, Student, Modul, Prüfung, Student2Prüfung.
Skript zum Erzeugen der University-Datenbank
| Top |
Es soll ein SQL-Skript erstellt werden, das
die Tabellen in der Reihenfolge: Studiengang, Student, Modul, Prüfung, Student2Prüfung erstellt.
Dafür werden die im folgenden angegebenen CREATE-Befehle einfach in eine Textdatei mit dem Namen
CreateDatabaseUniversity.sql gespeichert, dies wird in phpMyAdmin geladen, und ausgeführt.
Wir verwenden für die Tabellen- und Spalten-Namen hier deutsche Wörter mit Großbuchstaben und Umlauten,
dies kann abhängig vom verwendeten Betriebssystem und DBMS geändert werden.
Die Spalte ID (Datentyp int) wird in allen Tabellen mit der AUTO-INCREMENT-Eigenschaft versehen
und als Primärschlüssel festgelegt.
Die SQL-Anweisungen in der angegebenen Form funktionieren sowohl in MySQL als auch in SQL Server,
lediglich das Schlüsselwort AUTO_INCREMENT muss für SQL Server ersetzt werden durch IDENTITY(1,1).
Das Schlüsselwort NOT NULL bei einer Spalte bedeutet, dass bei Anlegen eines neuen Datensatzes ein Wert dafür
angegeben werden muss und sie nicht leer bleiben darf.
Tabelle Studiengang
Erzeuge eine Tabelle Studiengang mit den Spalten ID, Name, Art, den angegebenen Datentypen.
SQL-Anweisung (MySQL)
CREATE TABLE Studiengang (ID int NOT NULL AUTO_INCREMENT,Name varchar(100) NOT NULL,Art varchar(50) NOT NULL,PRIMARY KEY (ID))
Tabelle Student
Erzeuge eine Tabelle Student mit den Spalten ID, Name, Vorname, Matrikelnr, StudiengangID, Semester. Studenten können diesem Modell nach genau in einem Studiengang eingeschrieben sein, dies wird über den Fremdschüssel StudienggangID abgebildet.
SQL-Anweisung (MySQL)
CREATE TABLE Student(ID int NOT NULL AUTO_INCREMENT,Name varchar(255) NOT NULL,Vorname varchar(255) NOT NULL,Matrikelnr int UNIQUE,StudiengangID int NOT NULL,Semester int NULL,PRIMARY KEY (ID),CONSTRAINT FK_student_studiengangFOREIGN KEY (StudiengangID) REFERENCES Studiengang(ID) );
Tabelle Modul
Erzeuge eine Tabelle Modul mit den angegebenen Spalten und Datentypen. Primärschlüssel ist die Spalte ID.
SQL-Anweisung (MySQL)
CREATE TABLE Modul (ID int NOT NULL AUTO_INCREMENT,Name varchar(100) NOT NULL,Semester int DEFAULT NULL,CP int NOT NULL,SWS int NOT NULL,StudiengangID int NOT NULL,PRIMARY KEY (ID),CONSTRAINT FK_modul_studiengangFOREIGN KEY (StudiengangID) REFERENCES Studiengang(ID) );
Tabelle Prüfung
Erzeuge eine Tabelle Prüfung mit den angegebenen Spalten und Datentypen. Primärschlüssel ist die Spalte ID. Einem Modul können mehrere Prüfungen zugeordnet werden, umgekehrt kann eine Prüfung einem Modul zugeordnet werden, diese 1:n Beziehung wird über den Fremdschlüssel ModulID abgebildet.
SQL-Anweisung (MySQL)
CREATE TABLE Prüfung (ID int NOT NULL AUTO_INCREMENT,ModulID int NOT NULL,Semester int DEFAULT NULL,Jahr int DEFAULT NULL,Dozent varchar(100) NOT NULL,PRIMARY KEY (ID),CONSTRAINT FK_prüfung_modulFOREIGN KEY (ModulID) REFERENCES Modul(ID));
Tabelle Student2Prüfung
Die Tabelle Student2Prüfung bildet eine viele-zu-viele Beziehung zwischen Studenten und Prüfungen ab: ein Student hat viele Prüfungen, an einer Prüfung nehmen viele Studenten teil. In der Tabelle Student2prüfung werden auch die Noten gespeichert: Der Eintrag <1, 3, 1.7 > in dieser Tabelle bedeutet, dass der Student mit ID 1 in der Prüfung mit ID 3 die Note 1.7 erzielt hat.
SQL-Anweisung (MySQL)
CREATE TABLE Student2Prüfung (ID int NOT NULL AUTO_INCREMENT,StudentID int NOT NULL,PrüfungID int NOT NULL,Note double NOT NULL,PRIMARY KEY (ID),CONSTRAINT FK_s2p_student FOREIGN KEY (StudentID) REFERENCES Student(ID),CONSTRAINT FK_s2p_prüfung FOREIGN KEY (PrüfungID) REFERENCES Prüfung(ID));
Datensicht / View erstellen: CREATE VIEW
| Top |
Mit Hilfe des CREATE VIEW-Befehls können die Ergebnisse einer SELECT-Abfrage als Datensicht gespeichert werden. Views sind ein geeignetes Mittel, um die Komplexität einer Datenbank und technische Details zu verbergen, und ein höheres Abstraktionsniveau einzuführen.
Syntax
Nach dem Schlüsselwort CREATE VIEW wird der Name der View angegeben, gefolgt von dem Schlüsselwort AS, und einer SELECT-Anweisung, die die auszuführende Abfrage enthält.
CREATE VIEW View_Name ASSelect_Abfrage
Beispiel
Erzeuge eine Datensicht mit dem Namen Studenten_ET, die alle Studenten anzeigt, die Elektrotechnik studieren.
CREATE VIEW Studenten_ET ASSELECT Matrikelnr, Student.Name, Vorname, Studiengang.Name AS StgName, ArtFROM Student, StudiengangWHERE Student.StudiengangID = Studiengang.IDAND StgName LIKE '%Elektrotechnik%';
Gebe alle Studenten aus, die Elektrotechnik studieren. Jetzt muss nur noch die View abgefragt werden!
SELECT * FROM Studenten_ET;
5-2 ALTER: Strukturen ändern
| Top |
ALTER DATABASE ist der Befehl zum Ändern einer Datenbank. Der Befehl ist kein SQL Standard, wird jedoch von den meisten DBMS verwendet, allerdings in unterschiedlichen Ausprägungen. In SQL Server kann der ALTER DATABASE-Befehl verwendet werden, in MySQL nicht, hier ist das Umbenennen einer Datenbank aufwendiger.
Syntax (SQL Server)
ALTER DATABASE Datenbank MODIFY NAME = Neuer Name[Optionen];
Tabelle ändern: ALTER TABLE
| Top |
ALTER TABLE ist der Befehl zum Ändern einer Tabelle. Der Befehl wird verwendet, um einer Tabelle nachträglich Spalten oder Constraints hinzuzufügen.
Syntax: Spalten hinzufügen
Der SQL-Befehl zum nachträglichen Hinzufügen von Spalten ist wie folgt aufgebaut: Nach dem Schlüsselwort ALTER TABLE folgt der Name der zu ändernden Tabelle, danach das Schlüsselwort ADD, gefolgt von Spaltennamen mit Angabe des Datentyps und optionalen Angaben zu Constraints.
ALTER TABLE TabelleADD (Spalte1 Datentyp1 [Optionen],Spalte2 Datentyp2 [Optionen],[...]); /* Weitere Spalten */
Bei den Optionen kann z.B. ein Constraint wie DEFAULT, NOT NULL oder UNIQUE hinzugefügt werden.
Beispiel: Spalten hinzufügen (MySQL)
Hier fügen wir der Tabelle Student zwei Spalten hinzu: birthday, mit Datentyp DATE, darf nicht leer sein, und created, mit Datentyp DATETIME, erhält als Defaultwert den Zeitstempel beim Einfügen.
ALTER TABLE StudentADD (birthday date NOT NULL,created datetime DEFAULT current_timestamp());
Beispiel: Spalten hinzufügen (SQL Server)
Das nachträgliche Hinzufügen von Spalten in SQL Server hat eine ähnliche Syntax wie in MySQL, lediglich die Datentypen und Funktionen unterscheiden sich und müssen in der Dokumentation nachgeschlagen werden.
ALTER TABLE StudentADD (birthday date NOT NULL,created DATETIME2(3) DEFAULT SYSDATETIME()));
Syntax: Fremdschlüssel hinzufügen
Beim nachträglichen Hinzufügen eines Fremdschlüssel-Constraints wird nach dem ALTER TABLE-Schlüsselwort der Name der referenzierenden Tabelle (hier: Tabelle1) angegeben, danach das Schlüsselwort ADD, dann das Schlüsselwort FOREIGN KEY, der Name der referenzierenden Spalte in runde Klammern gesetzt, das Schlüsselwort REFERENCES, der Name der referenzierten Tabelle (hier: Tabelle2) und in runden Klammern die referenzierte Spalte in Tabelle2, meist der Primärschlüssel dieser Tabelle. Optional kann mit dem Schlüsselwort CONSTRAINT auch ein Name für den Fremdschlüssel-Constraint angegeben werden. Wird dieser Teil weggelassen, vergibt das DBMS automatisch einen Namen.
ALTER TABLE Tabelle1ADD [CONSTRAINT ConstraintName]FOREIGN KEY(FremdschlSpalte) Tabelle2(PrimärschlSpalte)
Beispiel: Spalten und Constraints hinzufügen
| Top |
In diesem Beispiel erstellen wir zunächst mit CREATE zwei Tabellen, Abteilung und Mitarbeiter. Jeder Mitarbeiter soll genau einer Abteilung zugeordnet sein. Um dies abzubilden, wird nachträglich mit ALTER TABLE der Tabelle Mitarbeiter die Spalte AbteilungID hinzugefügt, und es wird einen Fremdschlüssel auf diese Spalte gelegt. Die Spalte AbteilungID wird für jeden Mitarbeiter die ID der Abteilung speichern, der der Mitarbeiter angehört.
1 Tabellen erstellen
Tabelle Abteilung
CREATE TABLE Abteilung(ID int NOT NULL,Name varchar(50) UNIQUE,PRIMARY KEY(ID));
Tabelle Mitarbeiter
CREATE TABLE Mitarbeiter(ID int NOT NULL,Name varchar(50) NOT NULL,Vorname varchar(50) NOT NULL,Geburtsdatum date NOT NULL,Eintrittsdatum date NOT NULL,PRIMARY KEY(ID));
2 Tabelle Mitarbeiter ändern
Spalte hinzufügen
ALTER TABLE MitarbeiterADD AbteilungID int
Fremdschlüssel hinzufügen
ALTER TABLE MitarbeiterADD CONSTRAINT FKAbteilungMitarbeiterFOREIGN KEY(AbteilungID) REFERENCES Abteilung(ID)
5-3 DROP: Strukturen löschen
| Top |
Mit den DROP-Befehlen löscht man Datenbanken, Tabellen, Sichten, Events und weitere Datenbankobjekte. DROP-Befehle werden meist in der Phase des Datenbankentwurfs eingesetzt, oder in Export-Skripten. Insgesamt ist das Löschen kompletter Datenbankobjekte inklusive Inhalt eher selten erforderlich.
Datenbank löschen: DROP DATABASE
Syntax
DROP DATABASE Datenbank;
Tabelle löschen: DROP TABLE
Mit Hilfe des DROP TABLE-Befehls werden Tabellen gelöscht.
Syntax
DROP TABLE [IF EXISTS] Tabellen;
Falls es die angegebene Tabelle nicht gibt, erfolgt eine Fehlermeldung, es sei denn, man fügt das Schlüsselwort IF EXISTS hinzu. Falls von der zu löschenden Tabelle über Fremdschlüssel weitere Tabellen abhängen, erfolgt eine Fehlermeldung.
Beispiel: DROP TABLE
Die DROP TABLE-Befehle in diese Reihenfolge werden korrekt ausgeführt.
DROP TABLE IF EXISTS Student2Prüfung, Student; DROP TABLE IF EXISTS Prüfung, Modul, Studiengang;
Der folgende DROP TABLE-Befehl wird mit einer Fehlermeldung quittiert: Student hängt von Studiengang ab, daher kann Studiengang nicht zuerst gelöscht werden
-- So nicht, Fehler! DROP TABLE IF EXISTS Studiengang, Student;
5-4 TRUNCATE: Inhalte endgültig löschen
| Top |
TRUNCATE TABLE ist ein DDL-Befehl zum kompletten Löschen des Inhalts einer Tabelle, ähnlich wie DELETE ohne WHERE-Klausel. Im Unterschied zu DELETE setzt TRUNCATE TABLE den kompletten Inhalt plus einige Definitionseigenschaften der Tabelle zurück, und wird daher als DDL-Befehl bezeichnet. Weiterhin wird kein Transaktionsprotokoll für diese Aktion erstellt. Dies hat zur Folge, dass TRUNCATE TABLE gerade bei großen Tabellen mit vielen Datensätzen der effizientere Befehl ist, jedoch können die Änderungen nicht rückgängig gemacht werden.
TRUNCATE TABLE kann nicht verwendet werden, falls auf die Tabelle mit einer FOREIGN KEY-Einschränkung verwiesen wird.
Syntax
TRUNCATE TABLE Tabelle;
Beispiel
TRUNCATE TABLE Mitarbeiter;
6 Benutzer- und Rechteverwaltung
| Top |
Datenbankmanagementsysteme sind Client-Server-Systeme und unterstützen den Mehrbenutzerbetrieb, d.h. viele Benutzer können von verschiedenen Rechnern aus gleichzeitig Zugriff auf DBMS und Datenbanken haben. Benutzer können entsprechend den ihnen gewährten Berechtigungen Datenbanken erstellen, Daten manipulieren oder auch nur Abfragen an die Datenbank senden. Um Mehrbenutzerbetrieb fehlerfrei zu ermöglichen, verfügt jede DBMS über eine Benutzerverwaltung. Benutzer und Zugriffsrechte können entweder über die grafische Benutzeroberfläche des DBMS oder auch per SQL-Befehl erstellt werden.
- Der Datenbankadministrator ist zuständig für Verwaltung des DBMS, Datensicherung, Leistungsoptimierung, Zugriffsrechte. Der DBA hat die weitgreifendsten Berechtigungen: Server verwalten, Datenbanken erstellen / löschen, Daten manipulieren.
- Der Datenbankdesigner entwirft die Datenbank, entwickelt Sichten auf die Datenbank.
- Der Softwareentwickler entwickelt die Datenbankanwendung, d.h. den Client, deren Backend die Datenbank ist. Datenbankabfragen werden in eine Programmiersprache eingebettet. Der Programmierer ist oft auch der Datenbankdesigner, da viele Frameworks (z.B. die Java Persistence API) das Erstellen der Datenbankstruktur aus der Programmiersprache heraus ermöglichen.
- Der Endnutzer greift nur indirekt über eine Anwendung auf die Datenbank zu.
Die Benutzerverwaltung geschieht in zwei Schritten. Zunächst werden Benutzerkonten erstellt, dies geschieht mit Hilfe des CREATE USER-Befehls. Die SQL-Befehle GRANT und REVOKE werden anschließend für das Erteilen und Entziehen von Berechtigungen verwendet.
6-1 CREATE USER: Benutzer anlegen
| Top |
Mit Hilfe des SQL-Befehls CREATE USER können Benutzerkonten für ein DBMS angelegt werden, denen man anschließend Berechtigungen zuweisen kann.
Syntax: Benutzer anlegen
Beim Anlegen von Benutzerkonten wird ein Benutzername und ein Passwort vergeben, sowie ein Geltungsbereich festgelegt, d.h. von welchen Rechnern aus der Benutzer auf das DBMS zugreifen kann. Mittels Optionen kann weiterhin festgelegt werden, ob z.B. Passwort-Hashing verwendet wird, oder das Passwort abläuft, oder es können Einschränkungen festgelegt werden, wie viele offene Datenbank-Verbindungen der Benutzer pro Stunde haben kann.
CREATE USER benutzername IDENTIFIED[WITH Optionen]BY passwort;
Beispiel: Benutzer anlegen (MySQL)
In diesem Beispiel werden zwei Benutzerkonten angelegt, das erste mit lokalem, das zweite mit globalem Geltungsbereich.
CREATE USERuser1@localhost IDENTIFIED BY 'secret1',user2@:'%' IDENTIFIED BY 'secret2';
6-2 GRANT: Rechte erteilen
| Top |
Mit Hilfe des SQL-Befehls GRANT können Berechtigungen auf Datenbankobjekte an Benutzer oder Rollen erteilt werden. Die Option WITH GRANT OPTION bedeutet, dass der Benutzer seinerseits die Berechtigung an andere weitergeben kann.
Syntax: Rechte vergeben
Nach dem Schlüsselwort GRANT wird eine Liste von Berechtigungen angegeben, danach das Schlüsselwort ON, gefolgt von einer Liste von Datenbankobjekten, und dem Schlüsselwort TO, gefolgt von einer Liste von Benutzerkonten oder Rollen. Die Berechtigungen sind eine kommagetrennte Liste von Datenbankoperationen, z.B. "INSERT, UPDATE, DELETE". Es kann auch das Schlüsselwort ALL verwendet werden, um alle Berechtigungen zu erteilen / entziehen.
GRANT Berechtigungen ON DatenbankobjektTO {Benutzer | PUBLIC | Rolle}[WITH GRANT OPTION];
Beispiel (MySQL)
Benutzer anlegen und Rechte auf Datenbankebene vergeben
In diesem Beispiel werden drei Benutzer angelegt, user1, user2 und user3. Die ersten beiden Benutzer haben jeweils lokalen Geltungsbereich. Das dritte Konto user3 kann von jedem Rechner aus Zugriff haben. Benutzer user1 erhält alle Rechte bzgl. der Datenbank university. Benutzer user2 erhält die Rechte, Datenbankobjekte anzulegen und Daten zu manupulieren. Benutzer user3 erhält nur die Rechte, um DML-Operationen auf der Datenbank auszuführen, er kann also keine Datenbanken, Tabellen etc. anlegen, ändern oder löschen.
/* user1: Datenbankadmin */CREATE USER user1@localhost IDENTIFIED BY 'secret1';GRANT ALL PRIVILEGESON university.* TO user1@localhost;/* user2: Designer, Programmierer */CREATE USER user2@localhost IDENTIFIED BY 'secret2';GRANT CREATE, ALTER, DROP, SELECT, INSERT, UPDATE, DELETEON university.* TO user2@localhost;/* user3: Endnutzer, Poweruser */CREATE USER user3@'%' IDENTIFIED BY 'secret3';GRANT SELECT, INSERT, UPDATE, DELETEON university.* TO user3@'%';
Benutzer anlegen und Rechte auf Tabellenebene vergeben
Erteile dem Benutzer user4 das Recht, die Tabelle Student abzufragen sowie Daten einzufügen, zu ändern und zu löschen.
CREATE USER user4@localhostIDENTIFIED BY 'secret4';GRANT SELECT, INSERT, UPDATE, DELETE ONuniversity.Student TO user4@localhost;
6-3 REVOKE: Rechte entziehen
| Top |
Mit Hilfe des REVOKE-Befehls können Benutzern oder Rollen die Berechtigungen auf Datenbankobjekte entzogen werden.
Syntax: Rechte entziehen
REVOKE BerechtigungenFROM {Benutzer | PUBLIC | Rolle}
Beispiel (MySQL)
Rechte entziehen
Entziehe dem Benutzer user2 das Recht, die DDL-Befehle CREATE, ALTER, DROP auf den Objekten der Datenbank university zu erstellen.
REVOKE CREATE, ALTER, DROPON university.*FROM user2@localhost;
7 Transaktionen
| Top |
Eines der wichtigen weiterführenden Merkmale von Datenbanken ist die Unterstützung von Transaktionen. Eine Transaktion ist eine Gruppe elementarer Datenbankoperationen, die zusammen ausgeführt werden. Transaktionen werden eingesetzt, wenn in einer Datenbank mehrere logisch zusammenhängende Datensätze "ganz oder gar nicht" geändert werden müssen.
- Falls die Operationen vollständig abgearbeitet sind, wird der Datenbankzustand dauerhaft geändert, es wird ein COMMIT durchgeführt.
- Kann die vollständige Abarbeitung der Operationen der Transaktion nicht durchgeführt werden, werden alle durchgeführten Änderungen auf den Ausgangszustand zurückgesetzt, dann wird ein ROLLBACK durchgeführt.
- Eine einzelne Anweisung ist stets eine Transaktion und wird sofort ausgeführt ("autocommit"), kann im Fehlerfall jedoch nicht rückgängig gemacht werden.
Atomarität (Atomicity): Eine Transaktion wird ganz oder gar nicht ausgeführt.
Konsistenz (Consistency): Eine Transaktion führt von einem konsistenten in einen konsistenten Datenbankzustand.
Isolation (Isolation): Transaktionen paralleler Benutzer stören sich nicht gegenseitig.
Dauerhaftigkeit (Durability): Wenn eine Transaktion erfolgreich mit COMMIT abgeschlossen wurde, sind ihre Daten persistent gespeichert.
Unterschiedliche DBMS implementieren Transaktionen auf ähnliche Weise, mit ähnlicher Syntax und Wirkung.
Syntax (MySQL)
START TRANSACTION;-- [Anweisungen, die zusammen ausgeführt werden müssen]COMMIT; -- wird durchgeführt, falls kein Fehler auftrittSET autocommit = 1; -- Für weitere Anweisungen gilt Autocommit.
Syntax (SQL Server)
BEGIN TRANSACTION;-- [Anweisungen, die zusammen ausgeführt werden müssen]COMMIT TRANSACTION; -- wird durchgeführt, falls kein Fehler auftrittSET autocommit = 1; -- Für weitere Anweisungen gilt Autocommit.
Transaktionen werden häufig erst bei der Programmierung des Datenbank-Clients in die Persistenzschicht der Anwendung eingebaut. In der Datenbank-Persistenzschicht kann die Geschäftslogik der Anwendung abgebildet werden und es ist klar, welche Datenbankabfragen zusammengehören, dort können die COMMIT- und ROLLBACK-Vorgänge in passende TRY-CATCH-Blöcke eingebaut werden.
Tools, Quellen und weiterführende Links
Tools:
- [1] SQL Server Developer oder Express: microsoft.com/de-de/sql-server/sql-server-downloads
- [2] MariaDB: mariadb.org
- [3] MySQL: mysql.com
- [4] XAMPP: apachefriends.org
Quellen und weiterführende Links:
- [1] MySQL SQL-Referenz: dev.mysql.com/doc/refman/8.0/en/sql-statements.html
- [2] Erste Schritte mit phpMyAdmin: https://www.evamariakiss.de/tutorial/phpmyadmin/
- [3] SQL-Quiz: https://www.evamariakiss.de/tutorial/sqlquiz/
- [4] Edgar Frank Codd, "A Relational Model of Data for Large Shared Data Banks": bei ACM Digital Library - dieser Artikel führt die grundlegenden Begriffe des relationalen Datenmodells ein: Beziehung, Primärschlüssel, Fremdschlüssel.